
Overcoming regulatory roadblocks for Machine Learning models
Sip and Solve™ 15-Minute Webinar
Sip and Solve™ 15-Minute Webinar
Machine learning has been a buzzword for 50+ years in analytic circles and has created a stir in the last few years as its popularity and visibility increased in the US consumer and commercial credit industry. The use of these advanced methodologies has been constrained to mainly fraud/identity and collections. ML techniques are now available for credit decisioning. This session will provide some insights that will help your regulator feel more comfortable with the methodology you are using. Learn how Experian is making machine learning explainable to regulators and boosting model performance.
During this session you will learn three take-aways:
What follows is a lightly edited transcription of this Sip and Solve talk.
Hi everyone. And welcome to today's Sip and Solve. I'm Brody Oldham. I'm the Director of Analytic Consultancy with Experian Commercial Data Science team. I manage a team of consultants focused on commercial and small business analytics.
Today I have the privilege of walking you through and helping you overcome anxiety and hesitancy that you might have in the use of advanced modeling methodologies. We're going to do all this in about 15 minutes.
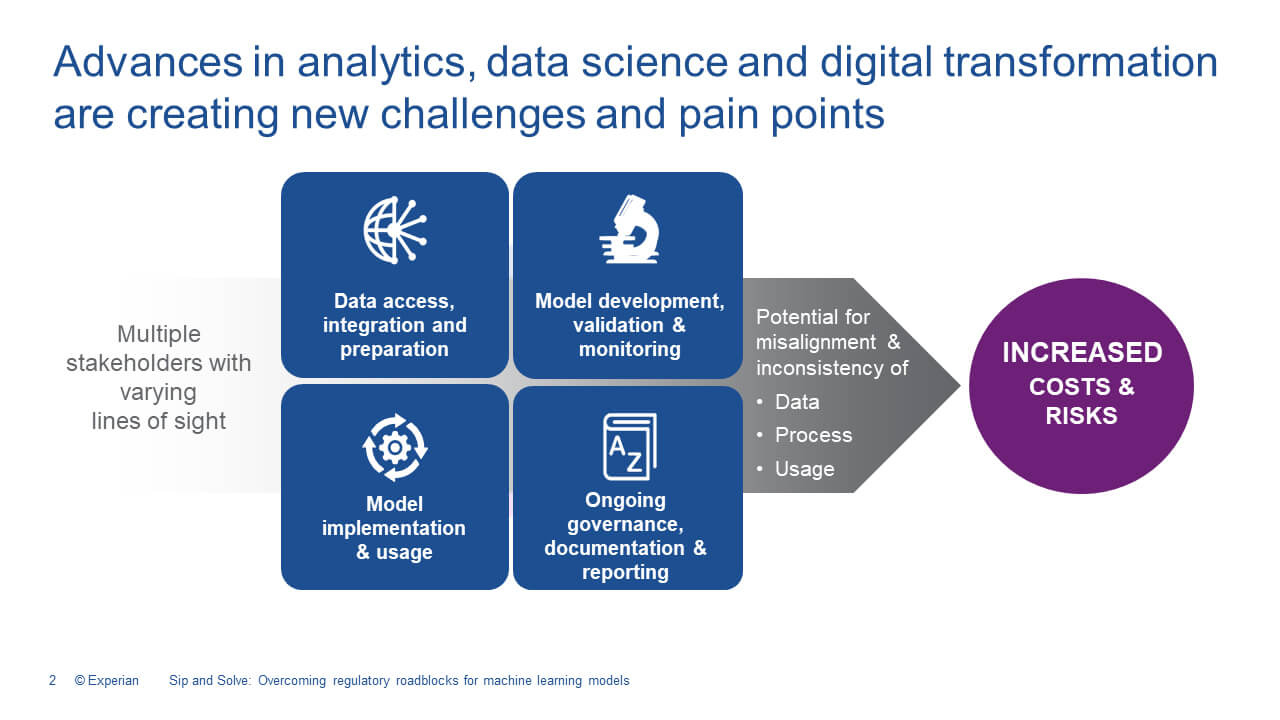
With all of the growing amounts of data, this proliferation of data, into our environment, it's been growing exponentially year over year, many companies are looking to integrate machine learning within their analytic model development and even credit decisioning. But why? Well, we've seen clients who use these methodologies see 15% to 20% performance improvement over their current champion models. Now that can be a significant increase in revenue creation and in recovery in a downturn like we're having now with COVID. It also helps lenders to make more accurate and informed decisions for customers, really, because these methods take in significantly more data to create a more holistic view of a customer or prospect.
There are several steps in deploying a machine learning model, and I always start with the deployment and discussing that with my stakeholders to ensure the types of methods that I'm evaluating will be deployable. I'm going to pour my time into optimizing and developing these machine learning models and these models take a lot of technical horsepower to process and meet decisioning SLA's for our clients. Off the shelf, we have models, machine learning models that make this pretty easy. So companies like Experian and certainly we do, and we're one of the leaders in the industry have these types of methodologies, easily accessible to you, but this is a topic that we can cover in another session. You should always have a pathway to deployment.
Once I've identified my stakeholders and walk through my deployment needs, I identify and pull the appropriate regulated and non-regulated data and prepare it for my development process. I say this pretty quick, but this is really essentially the step that takes the most time. It's the most important to my development process. When you get into a more advanced technique, you'll really see the need to consider what data's coming in, where the model is being fed from, and remember, these models can ingest large amounts of data variables, a lot more than a traditional model. Once you have the data and begin evaluating methods, you'll choose the method that performs the best, and you have really the ability to explain how it works. That's really the big criteria when we think about regulators or even internal reviewers. That can be a challenge with some of the techniques that are out there because they're complex and in some methodologies even have hidden layers of decisions.
So, let's think about machine learning. It's really an application of artificial intelligence, AI that is a synergistic exercise between human and a machine. The way to think about this is that systems learn from the data. They identify patterns, they solve problems. They make decisions and even make informed predictions. Within supervised learning, the machine learning algorithm is taught by example, and some of those examples of inputs and outputs, that are provided to the system, when they're put in the machine learning algorithm really provide the process of how to get from the indicators to the outcomes, and after some sufficient training, the system or algorithm produces an inferred function to make the prediction. Examples of these ML techniques include gradient boosting, random forests, and even neural networks. And you've probably heard of a few of these.
Once the model and documentation have been completed, model governance, compliance, legal reviews, conclude the model is deployed and quality control audits are completed to really ensure the model is performing very close to the development validation. The process doesn't end when you deploy though, you should never think that it's not a set it and forget it to make a regular regulator really comfortable with your new choice of methodology. You need to make the documentation and test results feel very familiar to that reviewer. You want to be able to explain how the model works in layman terms for the internal and external reviewer and where your new model should be used, and the capabilities that it has in the targets. Not every model can be used in a very general sense. Some are very focused on a particular outcome.
You also want to understand how often validations and monitoring need to be performed to ensure that the new methodology that you selected doesn't go off course and create additional headaches and cost. Remember, the reason that you're taking this path is that the reward is great for you and for your customer.

So now that we have a view of the considerations, let's tackle one of the biggest challenges companies like yours might face when a regulator or model governance reviewer shows up at your door. These methods can be a challenge because they are complex, they do have hidden layers of decisioning, and oftentimes you might not be familiar with them. So I've looked at several machine learning, explainability methods like a SHAP, Saabas, or LIME, and they're available and used by some of our clients. I've also been helping internally to develop some of our own. You'll need to find a methodology that works for your business. Experian can help you through the process and help you to develop an easily understandable talk track that really aligns with that method.
When you're looking at the challenge of transparency and that plays into that explainability discussion, there is a variety of offerings out there in the market. The need or focus of our work should really be leading toward developing the ability to explain the decisions that we're making to our end customers. And I really find these tree-based structures, like the gradient boosted technique, really the easiest. It produces an algorithm that's explainable without hidden layers. This generally lessons certain model governance concerns pertaining to the use of the machine learning technique, for credit scoring and decisioning. Because explaining how a tree-based decision is made can be easily visualized. And this understanding applies to a more advanced machine learning version.
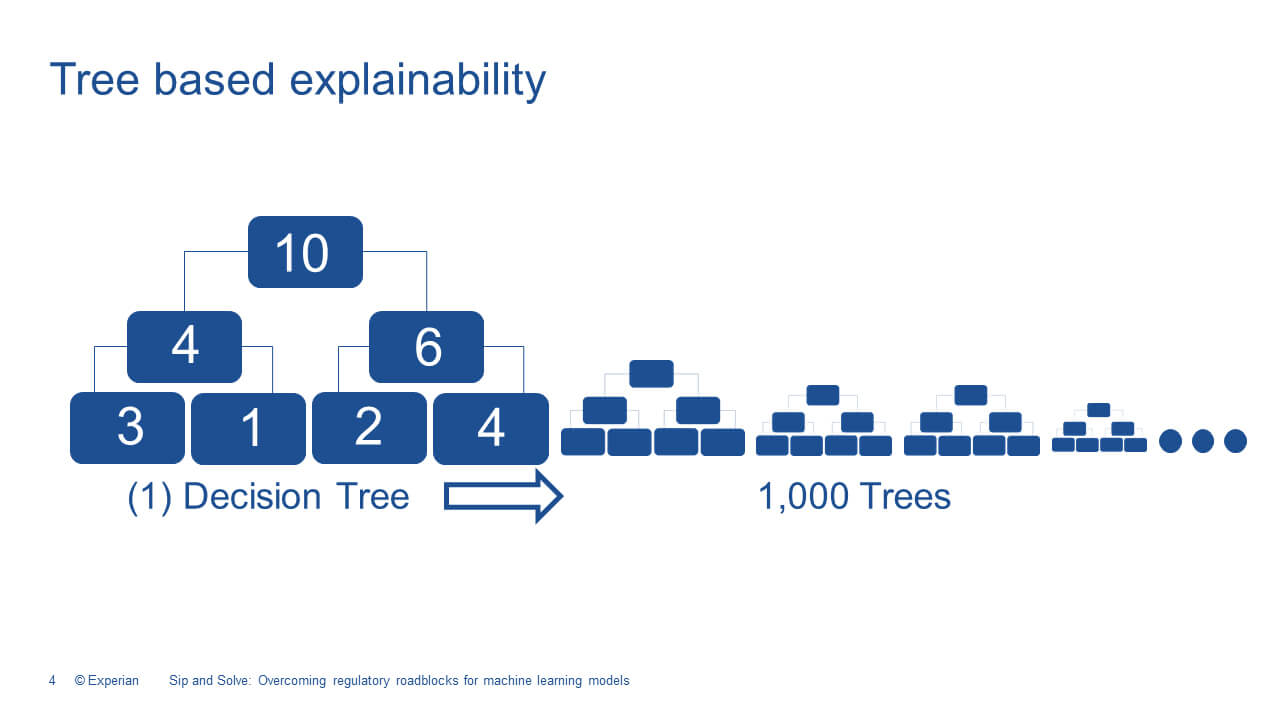
So, here's a quick and easy way to think about trees on the left is the first tree. You have 10 customers at the top, and as decisions are cascaded and made through the tree, customers fall into different buckets. And there's a different offer made at each of the bottom nodes based on the customer's risk. In machine learning, it's not just one tree, it's hundreds or thousands of trees. The methodology is the same in each of the individual trees. So, it's easy to understand how this type of segmentation works.

When you explain the tree-based and, and you can visualize a score, you really build trust in the accuracy of the decision, both globally and locally your end reviewer, whether you're compliance, risk, legal, regulator, even your end customer, you want to understand what contributed to that decision that was made, and adverse action codes are critical in this instance. Experian delivered and developed a machine learning methodology that provides consistent decisions and adverse action reasons for the life of the model.
So why is machine-learned when you'll hear that term from Experian, why is machine-learned different and easier to explain to a regulator? Well, the machine learning model is developed and trained using advanced methodologies and squeezing every little, last bit of performance out of the available data. And the model is transitioned, and you're going to listen for the difference in the words here, the model is transitioned from a dynamic machine learning model with an “ING”, and that's one that learns from feedback to a static machine-learned with an “ED” on the end model for deployment. This really means that the model will not change decisions based on feedback once it's deployed. The decisions are more predictive because they're using advanced techniques and methodologies, and really have a longer shelf life because they're not changing and moving with the environment.

Now that you have built your model, how do you take it from the perceived black box to a feeling of familiarity and comfort with the regulator? And, and I really, you know, when I think about today's events and the things that are happening and how all the things that are piling up on your plate, when you get in front of a regulator, you really want to hear peaceful music playing in the background. That would be a joy. To do that, you need to create really the standard model governance documentation that you're used to creating. Reports that provide a summary of performance metrics, such as KS, GINI, or Area Under the Curve, as well as a Correlation Matrix and List Curves. These reports are used to evaluate overall model performance and can be compared to other models developed using the same or competing methods. You need to show why you chose your desired method over all the others you tested. The most important part of creating this documentation is that it's very familiar to your internal model governance, as well as to the regulator. This establishes that baseline of trust and stability and performance in what you're creating.
I might recommend a few additional reports more specific to machine learning, and you can include some of these in your model documentation, I think they'll help. You can include an evaluation of model features or attributes such as a Target Plot. It gives you Feature Importance, Gain Coverage, Frequency, a Partial Dependency Plot, Individual, Conditional Expectations, or Permutation Feature Importance. All of these add to the detail and visualization of the individual features and their importance in the decision being made. And I would recommend that you also consider adverse action reporting. This is an easy one. It would contain a summary of the top four or five adverse actions, and this is going to help you and your regulator to understand which elements are the most impactful to the final decision you're making for your end customer.
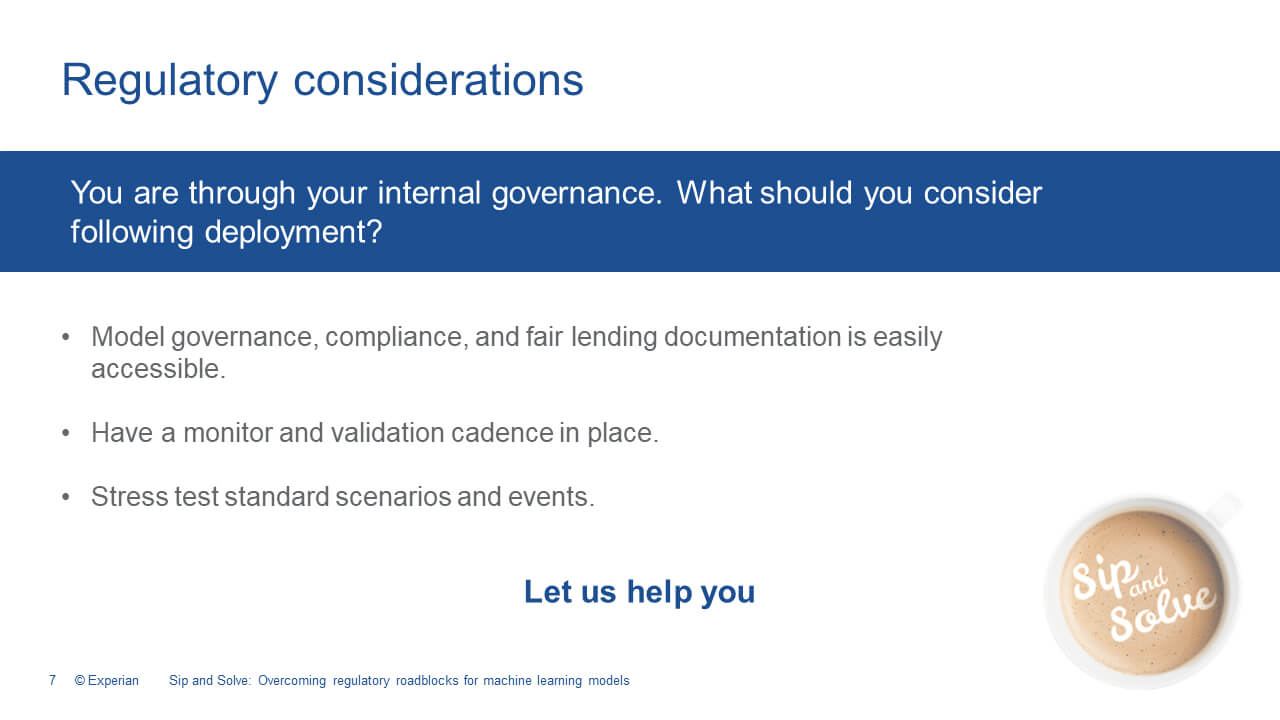
Getting in front of these concerns during the development stage is really important, and that's why we're here today to just get it out in front of you, give you a chance to really digest it. I think about it like cleaning my house. If you wait till all the way through the week until the weekend, you will end up spending all day Saturday cleaning, when you should be doing much more important and fun things. Innovating, be out there in front of your customers. So really being prepared and having your documentation up to date and in place, and in an easily accessible area so that you can make preparations for an audit quickly, and answer ad hoc questions more efficiently. That's going to make your regulator have trust in you that you have it all together.
Providing a monitoring and validation schedule will answer data and reporting freshness concerns that a regulator might have, is always a good thing to have on hand, and the cadence also fits within a governance framework in order to manage risk models across the model life cycle. I recommend also ensuring some full traceability of all the model and policy changes that you have throughout its lifetime. Having this change log really is going to help you improve by providing cause and effect responses, for performance irregularities that you might see across the lifetime of your model as it's installed. Regulators like to understand how models will be impacted by generic stress scenarios, and there are a few out there that are pretty standard, as well as events like COVID. it's the big one that we're dealing with now. The reporting you create will require some forward-looking information to be incorporated into the risk analysis, inferring performance for capital requirement calculations and policies is just good to have.
Experian can help you develop these processes, reports, provide some guidance as far as the numbers that you're calculating, the results, the targets that you're hitting, if they're in line with the industry, and help you to really develop your whole model governance framework. And remember we have these machine learning models right off the shelf with all the documentation already available.
Hopefully, I was able to help you overcome a few points of anxiety in regards to the explainability and reporting that is really going to help you feel more comfortable in using these very predictive, advanced modeling techniques and credit decisions. The familiarity that you find with standardizing reports and having everything prepared in your modeling framework is really going to help your regulator feel very comfortable and familiar with what you're producing as well and, and make audits go much more quickly.

Brodie Oldham leads a team of statistical consultants while remaining an active strategic statistical consultant for Commercial Data Sciences within Experian. He has 18+ years of experience in disciplines including analytics; database development; prospecting. In his current role, Brodie provides the marketing and sales organizations with customized analytic support. Prior to joining Experian, he worked at Citi Cards and Citi Mortgage as the Consumer Credit Risk Analytical Consultant.

